
OpenAI, zararlı yapay zeka tehdidine karşı iç güvenlik süreçlerini genişletiyor. Yeni bir “güvenlik danışma grubu” teknik ekiplerin üzerinde konumlanacak ve yönetime tavsiyelerde bulunacak; ayrıca yönetim kuruluna veto yetkisi de verildi.
TechCrunch’tan Devin Coldewey’in haberine göre, OpenAI, yeni bir belge ve blog yazısında, yönetim kurulunun iki üyesinin görevden alınmasıyla sonuçlanan Kasım ayındaki sarsıntıdan sonra güncellenmiş “Hazırlık Çerçevesi “ni tartışıyor: Yönetim Kurulu’ndan ayrılan Ilya Sutskever rolü biraz değişmiş olarak hala şirkette, ancak diğer üye Helen Toner şirketle yollarını tamamen ayırdı.
Güncellemenin temel amacı, geliştirmekte oldukları modellerin doğasında bulunan “felaket” risklerinin tanımlanması, analiz edilmesi ve ne yapılacağına karar verilmesi için net bir yol göstermek. Bu felaket şu şekilde tanımlanıyor:
“Felaket riski derken, yüz milyarlarca dolarlık ekonomik zarara yol açabilecek veya birçok kişinin ciddi şekilde zarar görmesine veya ölümüne neden olabilecek herhangi bir riski kastediyoruz; bu, varoluşsal riski de içerir, ancak bununla sınırlı değil.”
(Varoluşsal risk, “makinelerin yükselişi” türü şeyler).
Üretimdeki modeller bir “güvenlik sistemleri” ekibi tarafından yönetiliyor; bu, örneğin API kısıtlamaları veya ayarlamalarıyla hafifletilebilecek ChatGPT’nin sistematik suistimalleri için. Geliştirme aşamasındaki sınır modeller, model yayınlanmadan önce riskleri belirlemeye ve ölçmeye çalışan “hazırlık” ekibine sahip. Bir de “süper hizalama” ekibi var ki, bu ekip “süper akıllı” modeller için teorik kılavuz raylar üzerinde çalışıyor.
Kurgusal değil gerçek olan ilk iki kategorinin anlaşılması nispeten kolay bir değerlendirme tablosu oluşturuyor. Ekipler her modeli dört risk kategorisine göre değerlendiriyor: siber güvenlik, “ikna” (örneğin dezenformasyon), model özerkliği (yani kendi başına hareket etme) ve KBRN (kimyasal, biyolojik, radyolojik ve nükleer tehditler; örneğin yeni patojenler yaratma yeteneği – CBRN / chemical, biological, radiological, and nuclear threats).
Çeşitli hafifletmeler varsayılmış durumda: Örneğin, napalm veya boru bombası yapım sürecini tanımlamak için makul bir suskunluk. Bilinen hafifletmeler dikkate alındıktan sonra, bir model hala “yüksek” riske sahip olarak değerlendiriliyorsa, konuşlandırılamaz ve bir model “kritik” risklere sahipse, daha fazla geliştirilmeyecek.
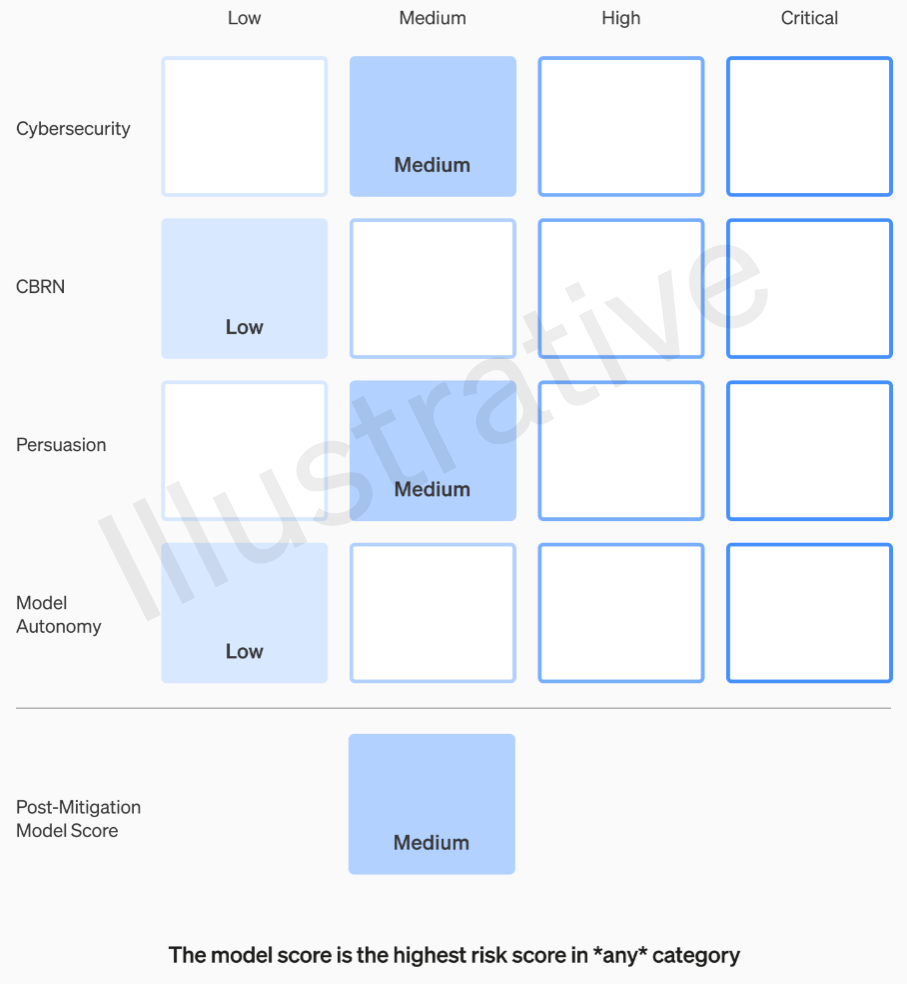
Bu risk seviyeleri aslında çerçevede belgelenmiş, eğer bunların bir mühendisin veya ürün müdürünün takdirine bırakılıp bırakılmayacağını merak ediyorsanız.
Örneğin, en pratik olan siber güvenlik bölümünde, “kilit siber operasyon görevlerinde operatörlerin verimliliğini … artırmak” belirli bir faktör tarafından “orta” bir risk. Öte yandan yüksek riskli bir model, “insan müdahalesi olmadan sertleştirilmiş hedeflere karşı yüksek değerli istismarlar için kavram kanıtlarını belirleyecek ve geliştirecek.” Kritik olan ise “modelin, yalnızca yüksek düzeyde istenen bir hedef verildiğinde, sertleştirilmiş hedeflere yönelik siber saldırılar için uçtan uca yeni stratejiler tasarlayabilmesi ve yürütebilmesi.” Açıkçası bunu dışarıda istemiyoruz (yine de oldukça yüksek bir meblağa satılabilir).
OpenAI’den bu kategorilerin nasıl tanımlandığı ve rafine edildiği hakkında daha fazla bilgi istedim (örneğin, insanların fotogerçekçi sahte videoları gibi yeni bir riskin “ikna” ya da yeni bir kategori altına girip girmediği).
Dolayısıyla, sadece orta ve yüksek riskler bir şekilde tolere edilmeli. Ancak bu modelleri yapan kişiler, onları değerlendirecek ve tavsiyelerde bulunacak en iyi kişiler olmayabilir. Bu nedenle OpenAI, teknik tarafın üstünde yer alacak, uzmanların raporlarını gözden geçirecek ve daha yüksek bir bakış açısını içeren tavsiyelerde bulunacak bir “çapraz fonksiyonel Güvenlik Danışma Grubu” oluşturuyor. Bunun bazı “bilinmeyen bilinmeyenleri” ortaya çıkaracağını umuyoruz (diyorlar), ancak doğası gereği bunları yakalamak oldukça zor.
Süreç, bu tavsiyelerin eş zamanlı olarak yönetim kuruluna ve CEO Sam Altman ve CTO Mira Murati’nin yanı sıra onların yardımcıları anlamına geldiğini anladığımız liderliğe gönderilmesini gerektiriyor. Liderlik, sevkiyat ya da buzdolabına koyma kararını verecek, ancak yönetim kurulu bu kararları tersine çevirebilecek.
Anthropic’in politikasıyla bir tezat
OpenAI’nin duyurusu, eski OpenAI araştırmacıları tarafından kurulan bir diğer önde gelen yapay zeka laboratuvarı olan baş rakibi Anthropic’in yapay zeka güvenliğine odaklanan birkaç önemli sürümünün ardından geldi. Gizli ve seçici yaklaşımıyla tanınan Anthropic, yakın zamanda belirli Sorumlu Ölçeklendirme Politikası‘ni yayınladı. Yapay Zeka Güvenlik Düzeyleri ve yapay zeka modellerini geliştirmek ve dağıtmak için ilgili protokoller.
İki çerçeve, yapıları ve metodolojileri bakımından önemli ölçüde farklılık gösteriyor. Anthropic’in politikası daha resmi ve kuralcıdır; güvenlik önlemlerini doğrudan model yeteneklerine bağlıyor ve güvenlik kanıtlanamazsa geliştirmeyi duraklatıyor. OpenAI’nin çerçevesi daha esnek ve uyarlanabilir olup, önceden tanımlanmış seviyeler yerine incelemeleri tetikleyen genel risk eşiklerini belirliyor.
Uzmanlar, her iki çerçevenin de avantajları ve dezavantajları olduğunu söylüyor ancak Anthropic’in yaklaşımının, güvenlik standartlarını teşvik etme ve uygulama açısından bir avantajı olabilir. Analizimize göre, Anthropic’in politikası güvenliği geliştirme sürecine dahil ederken, OpenAI’nin çerçevesi daha gevşek ve daha ihtiyari kalarak insanın muhakemesine ve hatasına daha fazla yer bırakıyor.
Bazı gözlemciler ayrıca OpenAI’nin, GPT-4 gibi modellerin hızlı ve agresif dağıtımı nedeniyle tepkiyle karşılaştıktan sonra güvenlik protokollerini yakalamaya çalıştığını da görüyor, gerçekçi ve ikna edici metinler üretebilen en gelişmiş büyük dil modeli. Anthropic’in politikası kısmen, tepkisel olmaktan ziyade proaktif olarak geliştirilmiş olması nedeniyle avantajlı olabilir.
Farklılıkları ne olursa olsun, her iki çerçeve de yapay zeka yetenekleri arayışının sıklıkla gölgede bıraktığı yapay zeka güvenliği alanında ileriye doğru atılmış önemli bir adımı temsil ediyor. Yapay zeka modelleri daha güçlü ve her yerde bulunur hale geldikçe, önde gelen laboratuvarlar ve paydaşlar arasında güvenlik teknikleri konusunda işbirliği ve koordinasyon artık yapay zekanın insanlık için faydalı ve etik kullanımını sağlamak için hayati önem taşıyor.
Kaynaklar: TechCrunch / Venturebeat
Yapayzeka.news’in hiçbir güncellemesini kaçırmamak için bizi Facebook, Twitter, LinkedIn, Instagram‘ ve Whatsapp Kanalımız‘dan takip edin.


{kind=link}