
Google, alternatif modellerden daha iyi performans gösteren ve yeni bir standart olarak görülebilecek yeni bir metinden videoya modelini tanıttı.
Google araştırmacıları, alternatif yaklaşımların birçok sorununun üstesinden gelen gerçekçi yapay zeka videoları üretebilen Lumiere adlı yeni bir metinden videoya (T2V) yayılım modeli geliştirdi.
Google just made an incredible AI video breakthrough with its latest diffusion model, Lumiere.
2024 is going to be a massive year for AI video, mark my words.
Here’s what separates Lumiere from other AI video models: pic.twitter.com/PulSjVZaCp
— Rowan Cheung (@rowancheung) January 25, 2024
Lumiere, tutarlı hareket ve yüksek kaliteye sahip videoların üretilmesini sağlayan yeni bir Uzay-Zaman U-Net (STUNet) mimarisi kullanıyor. Yöntem, bir seferde videonun yalnızca bir kısmını işleyebilen bir dizi modele dayanan önceki yaklaşımlardan temelde farklı.
Lumiere ayrıca video boyama, görüntüden video oluşturma ve stilize video gibi diğer uygulamalar için de kullanılabilir. Model 30 milyon video üzerinde eğitildi ve diğer yöntemlerle karşılaştırıldığında video kalitesi ve metin eşleştirme açısından rekabetçi sonuçlar gösteriyor. Model, ilgili metin başlıklarıyla birlikte 30 milyon video üzerinde eğitildi. Videolar saniyede 16 kare (fps) hızında 80 kare uzunluğunda ve her biri 5 saniye sürüyor. Model, zamansal boyut gibi video ile ilgili yönler için ek katmanlarla genişletilen önceden eğitilmiş dondurulmuş bir metin-görüntü modeline dayanıyor.
Google’ın Lumiere’i uzamsal ve zamansal aşağı ve yukarı örneklemeye dayanıyor
Önce ana kareler oluşturan ve ardından bu ana kareler arasına eksik kareler eklemek için Temporal Super-Resolution (TSR) modellerini kullanan önceki T2V modellerinin aksine, Lumiere tüm video dizisini bir kerede oluşturuyor. Bu, video boyunca daha tutarlı ve gerçekçi hareket sağlıyor.
Bu, mevcut yöntemler gibi yalnızca uzamsal çözünürlüğü değil, aynı zamanda zamansal çözünürlüğü de aşağı örnekleyen ve ardından yukarı örnekleyen STUNet mimarisi ile mümkün oluyor. Bir videodaki saniye başına kare sayısı aşağı örneklenir ve ardından tekrar yukarı örneklenir. Alt örnekleme ile model videoyu bu azaltılmış zamansal çözünürlükte işler, ancak yine de videonun tüm uzunluğunu görür, sadece daha az kare ile. Bu şekilde model, nesnelerin ve sahnelerin bu azaltılmış kare sayısı boyunca nasıl hareket ettiğini ve değiştiğini öğrenir.
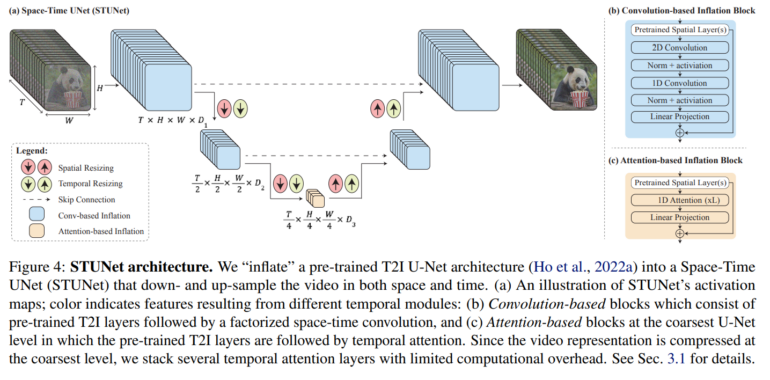
Model bu düşük çözünürlükte temel hareket modellerini öğrendikten sonra, tam zamansal çözünürlükte nihai video kalitesini iyileştirmek için bunların üzerine inşa edebilir. Bu süreç, oluşturulan hareket ve sahnelerin kalitesinden ödün vermeden videonun daha verimli bir şekilde işlenmesini sağlar.
Video bu düşük zamansal ve uzamsal çözünürlükte oluşturulduktan sonra, Lumiere uzamsal süper çözünürlük (SSR) için Multidiffusion kullanıyor. Bu, videonun üst üste binen segmentlere bölünmesini ve çözünürlüğü artırmak için her bir segmentin ayrı ayrı geliştirilmesini içeriyor. Bu segmentler daha sonra tutarlı, yüksek çözünürlüklü bir video oluşturmak için bir araya getiriliyor. Bu işlem, doğrudan yüksek çözünürlüklü üretim için gereken devasa kaynaklar olmadan yüksek kaliteli video üretmeyi mümkün kılıyor.
Google’a göre Lumiere, bir kullanıcı çalışmasında Imagen Video, Pika, Stable Video Diffusion ve Gen-2 gibi mevcut metin-video modellerinden daha iyi performans gösterdi. Güçlü yönlerine rağmen, yapılması gereken çok şey var: Lumiere ayrıca birden fazla sahne veya sahneler arasında geçişler içeren videolar oluşturmak için tasarlanmadığını anımsatalım; bu da gelecekte araştırmalar için bir zorluk oluşturuyor.
Bu arada, model üzerinde Google ile çalışan öğrenci araştırmacı Hila Chefer, modelin yeteneklerine ilişkin bir örneği sosyal medya platformu X’te yayınladı:
TLDR: Meet ✨Lumiere✨ our new text-to-video model from @GoogleAI!
Lumiere is designed to create entire clips in just one go!
Seamlessly opening up possibilities for many applications:
Image-to-video 🖼️ Stylized generation 🖌️ Video editing 🪩 and beyond.See 🧵👇 pic.twitter.com/Szj8rjN2md
— Hila Chefer (@hila_chefer) January 24, 2024
X kullanıcıları bu gelişmeyi “inanılmaz bir atılım” ve “son teknoloji ürünü” gibi ifadelerle yorumladı ve gelecek yıl video oluşturmanın “çıldıracağını” öngörenler bile oldu.
Googles new video model Lumiere can stylize motion by looking at a single image, and it looks pretty good.
Generative video is gonna get crazy this year you guys
— Nick St. Pierre (@nickfloats) January 24, 2024
Öte yandan, Google’ın modeli eğitmek için kullandığı verilerin kaynağından hiç söz etmemesi dikkat çekti; bu, yapay zeka ve telif hakkı yasası dünyasında çokça konuşulan bir konu ve yeni bir tartışmayı daha başlatabilir.
Daha fazla örnek ve bilgi için Lumiere proje sayfasını ziyaret edebilirsiniz.
Yapayzeka.news’in hiçbir güncellemesini kaçırmamak için bizi Facebook, Twitter, LinkedIn, Instagram‘ ve Whatsapp Kanalımız‘dan takip edin.


{kind=link}