Meta, UC Berkeley ve NYU’dan bilim insanları, büyük dil modellerinin (LLM’ler) genel görevlere nasıl yaklaştığını iyileştirmek için yeni bir teknik oluşturdular. “Düşünce Tercihi Optimizasyonu” (TPO) adı verilen yöntem, yapay zeka sistemlerinin yanıt vermeden önce yanıtlarını daha dikkatli bir şekilde değerlendirmesini sağlamayı amaçlıyor.
Araştırmacılar, “Biz düşünmenin geniş bir faydası olması gerektiğini savunuyoruz. Örneğin, yaratıcı bir yazma görevinde, içsel düşünceler genel yapıyı ve karakterleri planlamak için kullanılabilir” diye açıklıyor.
Bu yaklaşım, esas olarak matematik ve mantık görevleri için kullanılan önceki “düşünce zinciri” (CoT) istem tekniklerinden farklı. Araştırmacılar, düşünmenin daha geniş bir görev yelpazesine fayda sağlayabileceği tezlerini desteklemek için OpenAI’nin yeni o1 modelini gösteriyorlar.
Ek veri olmadan eğitim
TPO, insan düşünce süreçlerini içeren sınırlı eğitim verilerinin zorluğunun üstesinden geliyor. Şu şekilde çalışıyor:
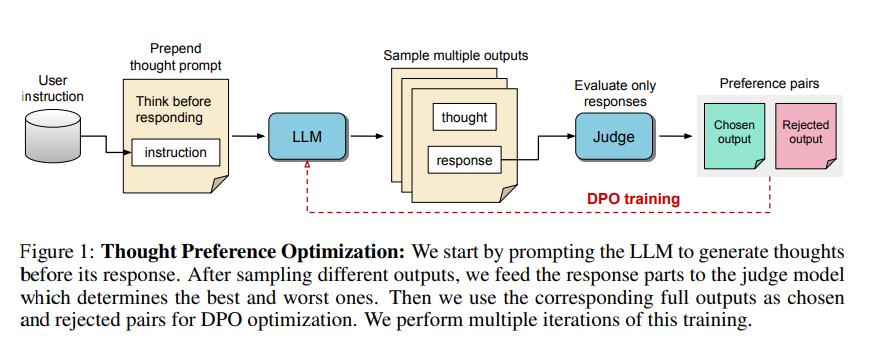
1. Cevap vermeden önce modelden düşünce adımları üretmesini istemek.
2. Birden fazla çıktı oluşturmak.
3. Yalnızca son cevapları değerlendirmek için bir değerlendirici model kullanmak.
4. Bu değerlendirmelere dayalı tercih optimizasyonu yoluyla modeli eğitmek.
Düşünce adımlarının kendileri doğrudan değerlendirilmiyor, yalnızca sonuçları değerlendiriliyor. Araştırmacılar daha iyi yanıtların gelişmiş düşünce süreçleri gerektireceğini ve modelin örtük olarak daha etkili akıl yürütmeyi öğrenmesine izin vereceğini umuyor.
Bu yöntem, OpenAI’nin o1 modeliyle yaklaşımından önemli ölçüde farklı. o1 için kesin eğitim süreci belirsiz olsa da, muhtemelen açık düşünce süreçleriyle yüksek kaliteli eğitim verilerini içeriyor. Ek olarak, o1 düşünce adımlarını analiz için metin olarak çıktı olarak vererek aktif olarak “düşünüyor”.
Bazı kategorilerde iyileştirmeler
Genel talimat takibi için kıyaslamalarda test edildiğinde, TPO kullanan bir Llama 3 8B modeli, açık bir gerekçe olmaksızın versiyonları geride bıraktı. AlpacaEval ve Arena-Hard kıyaslamalarında, TPO sırasıyla %52,5 ve %37,3 kazanma oranlarına ulaştı.
Gelişmeler geleneksel muhakeme görevleriyle sınırlı değildi. TPO, genel bilgi, pazarlama veya sağlık gibi genellikle açık düşünmeyle ilişkilendirilmeyen alanlarda da kazanımlar gösterdi.
Araştırmacılar, “Bu, daha dar teknik alanlarda uzmanlaşmak yerine genel eğitime yönelik Düşünme LLM’leri geliştirmek için yeni bir fırsat yaratıyor” sonucuna vardılar.
Ancak ekip, mevcut kurulumun, performansın temel modele kıyasla aslında düştüğü matematik problemleri için uygun olmadığını belirtiyor. Bu, oldukça uzmanlaşmış görevler için farklı yaklaşımlara ihtiyaç duyulabileceğini gösteriyor.
Gelecekteki çalışmalar, düşüncelerin uzunluğunu daha kontrol edilebilir hale getirmeye ve düşünmenin daha büyük modeller üzerindeki etkilerini araştırmaya odaklanabilir.
Kaynak: The Decoder
Yapayzeka.news’in hiçbir güncellemesini kaçırmamak için bizi Facebook, X (Twitter), Bluesky, LinkedIn, Instagram ve Whatsapp Kanalımız‘dan takip edin.


 genel görevlere nasıl yaklaştığını iyileştirmek için yeni bir teknik oluşturdular.){kind=link}