
OpenAI sonunda “Strawberry” projesi hakkında detayları açıkladı: o1 adlı yeni bir AI modeli. Bu model, AI mantığı için yeni bir standart belirlemeyi amaçlayan soruları işlemek için daha fazla zaman harcamak üzere tasarlandı. Tüm görevlerde üstün olmasa da o1, artan hesaplama yoluyla yeni bir ölçekleme ufku yaratmayı amaçlıyor.
OpenAI, o1’i “önemli bir ilerleme” ve “yapay zeka yeteneğinin yeni bir seviyesi” olarak tanımlıyor. Model, cevap vermeden önce dahili bir “düşünce sürecinden” geçmesi için takviyeli öğrenme kullanılarak eğitildi.
Modelin ortak geliştiricisi Noam Brown şöyle açıklıyor: “OpenAI o1, özel bir düşünce zinciri aracılığıyla yanıt vermeden önce ‘düşünmek’ için RL ile eğitildi. Ne kadar uzun süre düşünürse, muhakeme görevlerinde o kadar iyi performans gösteriyor.”
Bu, Project Strawberry hakkında daha önce yapılan varsayımlara karşılık geliyor. Brown’a göre bu, ölçekleme için yeni bir boyut açıyor. Brown, “Artık ön eğitimle darboğazda değiliz. Artık çıkarım hesaplamasını da ölçekleyebiliyoruz” diyor.
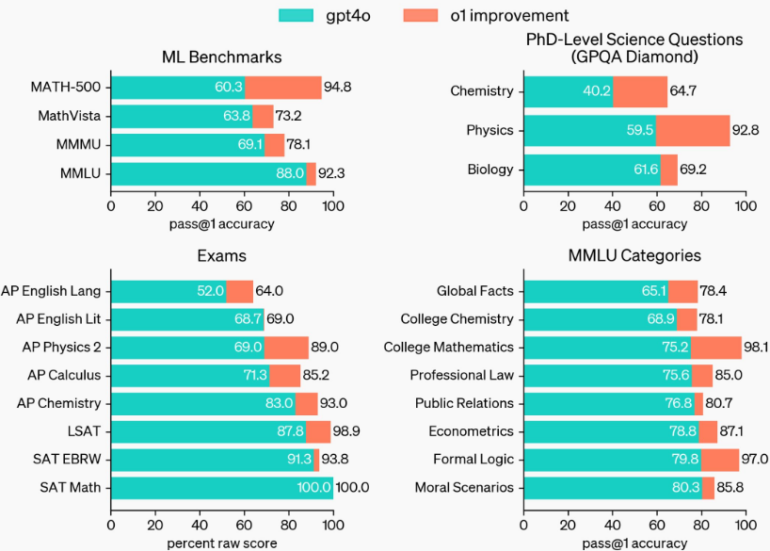
o1, özellikle mantık görevlerinde GPT-4o’dan daha iyi performans gösteriyor. Doktora sonuçları, Microsoft CTO Doktora yorumlarının nereden kaynaklandığı olabilir.
Mantık tabanlı görevler için en uygunudur
o1 modellerinin selefleri GPT-4o’dan her alanda daha iyi performans göstermediğini belirten Brown, “o1 modellerimiz her zaman GPT-4o’dan daha iyi değil. Birçok görevin akıl yürütmeye ihtiyacı yok ve bazen hızlı bir GPT-4o yanıtı yerine o1 yanıtını beklemeye değmez” diyor.
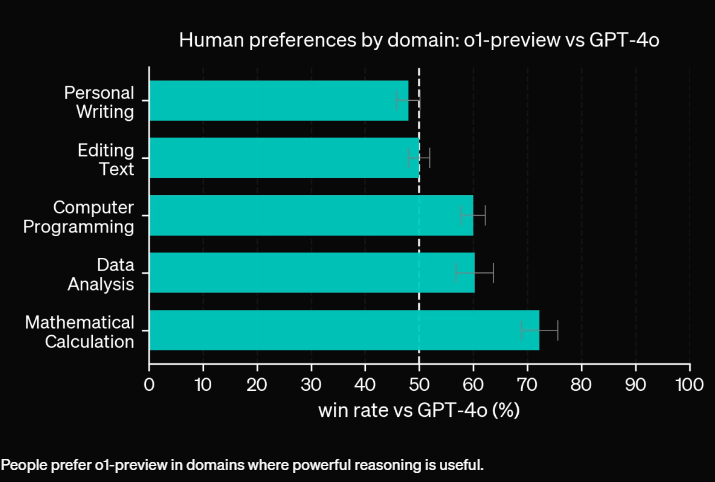
İnsanlar GPT-4o’nun çıktısını yazma ve düzenleme görevlerinde daha iyi değerlendirirken, yeni model mantıkta üstünlük sağlıyor.
OpenAI, en uygun kullanım durumlarını ve iyileştirme alanlarını belirlemek için o1’in küçültülmüş bir versiyonu olan o1-preview’u yayınladı. Brown şunları kabul ediyor:
“OpenAI o1-preview mükemmel değil. Bazen üç taş oyununda bile tökezliyor. İnsanlar başarısızlık durumlarını tweetliyor. Ancak insanların ‘LLM’ler akıl yürütemez’i göstermek için kullandıkları birçok popüler örnekte, o1-preview çok daha iyisini yapıyor, o1 harikalar yaratıyor ve biz onu daha da nasıl ölçeklendireceğimizi biliyoruz.”
Daha fazla bilgi işlem gücü, daha iyi düşünme
Şu anda o1, yanıt vermeden önce yalnızca birkaç saniye düşünüyor. Ancak gelecekte OpenAI’nin vizyonu, modelin bir yanıt hakkında saatler, günler hatta haftalar boyunca düşünebilmesi.
Bu, çıkarım maliyetini artırırken, yeni ilaçlar geliştirmek veya Riemann Hipotezini kanıtlamak gibi çığır açan uygulamalar için haklıdır. Brown, “AI, sohbet robotlarından daha fazlası olabilir” diyor.
OpenAI, o1-preview ve o1-mini modellerini ChatGPT üzerinden anında kullanıma sundu. Şirket ayrıca henüz tamamlanmamış o1 modeli için değerlendirme sonuçlarını da yayınlıyor.
Brown, amacın bunun tek seferlik bir iyileştirme olmadığını, AI modellerini ölçeklendirmek için yeni bir paradigma olduğunu göstermek olduğunu söylüyor ve “Daha başlangıçtayız” diyor.
STEM görevleri için O1-mini
o1-preview’un yanı sıra OpenAI, STEM uygulamaları için optimize edilmiş daha uygun maliyetli bir sürüm olan o1-mini’yi tanıttı. O1-mini, matematik ve programlama görevlerinde o1 ile neredeyse aynı performansı elde ediyor ancak önemli ölçüde daha düşük bir maliyetle. Bir lise matematik yarışmasında o1-mini, o1’in puanının %70’ini alırken, o1-preview yalnızca %44,6’ya ulaştı.
Codeforces platformundaki programlama zorluklarında o1-mini, o1 (1673) kadar iyi performans gösteriyor ve o1-preview’dan (1258) önemli ölçüde daha iyi bir performans gösteriyor ve 1650’lik bir Elo puanına sahip. HumanEval kodlama kıyaslamasında, o1 modelleri (%92,4) GPT-4o’dan (%90,2) yalnızca biraz önde.
OpenAI’ye göre, o1-mini’nin STEM odaklı olması nedeniyle diğer alanlardaki genel bilgisi GPT-4o mini gibi daha küçük dil modellerine benziyor.
ChatGPT Plus ve Team kullanıcıları o1-preview ve o1-mini’ye hemen erişebilirken, Enterprise ve Edu kullanıcıları önümüzdeki hafta başında erişime kavuşacak. OpenAI, o1-mini’yi tüm ücretsiz ChatGPT kullanıcılarına sunmayı planlıyor ancak bir yayın tarihi belirlemedi.
API’de, o1-preview 1 milyon giriş belirteci başına 15$ ve 1 milyon çıkış belirteci başına 60$’a mal olur. GPT-4o 1 milyon giriş belirteci başına 5$ ve 1 milyon çıkış belirteci başına 15$ ile önemli ölçüde daha ucuzdur. OpenAI, O1-mini’nin Tier 5 API kullanıcıları için mevcut olduğunu ve o1-preview’dan yüzde 80 daha ucuz olduğunu söylüyor.
Nvidia araştırmacısı: OpenAI’nin yeni Strawberry modeli hesaplamayı eğitimden çıkarıma kaydırıyor
Nvidia’da bir AI araştırmacısı olan Jim Fan, OpenAI’nin yeni modelinin şirket dışından ilk uzman değerlendirmelerinden birini sağladı. Fan, bir LinkedIn gönderisinde 01’in daha önce çoğunlukla araştırmada tartışılan çıkarım ölçekleme paradigmasını üretime getirdiğini belirtiyor.
Fan’a göre, mantıksal akıl yürütme modelleri muazzam olmak zorunda değil. Birçok parametre, bilgi testleri gibi kıyaslamalarda iyi performans göstermek için öncelikle gerçekleri depolar. Mantığı ve bilgiyi, tarayıcılar ve kod doğrulayıcıları gibi araçları nasıl çağıracağını bilen küçük bir “akıl yürütme çekirdeğine” ayırmak mümkündür, bu da potansiyel olarak eğitim öncesi hesaplama gereksinimlerini azaltır.
Bunun yerine, Strawberry hesaplamanın çoğunu çıkarıma kaydırır. Fan, dil modellerinin metin tabanlı simülatörler olduğunu açıklar. Birçok olası strateji ve senaryoyu oynayarak, model sonunda iyi çözümlere yakınsar. Fan, OpenAI’nin çıkarım ölçekleme yasasını bir süredir anlamış olabileceğini, ancak bilim camiasının ancak şimdi yetiştiğini öne sürer.

Çoğu LLM, ön eğitime büyük yatırım yaparken, Strawberry çıkarıma daha büyük bir pay ayırır. Ön ve son eğitim daha küçük bir rol oynar.
Ancak Fan, o1’i ürünleştirmenin en iyi akademik ölçütlere ulaşmaktan çok daha zorlayıcı olduğunu belirtiyor. Gerçek dünya mantık problemleri için, aramayı ne zaman durduracağınız, hangi ödül işlevlerini ve başarı ölçütlerini kullanacağınız ve kod yorumlayıcıları gibi araçları ne zaman dahil edeceğiniz konusunda kararlar alınmalıdır. Bu CPU süreçlerinin hesaplama maliyeti de dikkate alınmalıdır.
Fan, Strawberry’nin bir veri çarkı olabileceğine inanıyor. Cevaplar doğru olduğunda, tüm arama izi, olumlu ve olumsuz ödüllerle eğitim örneklerinin mini bir veri kümesi haline gelir ve gelecekteki GPT sürümleri için “akıl yürütme çekirdeğini” potansiyel olarak iyileştirebilir.
Kaynak: The Decoder
Yapayzeka.news’in hiçbir güncellemesini kaçırmamak için bizi Facebook, X (Twitter), Bluesky, LinkedIn, Instagram ve Whatsapp Kanalımız‘dan takip edin.


{kind=link}