
Araştırmacılar GOT (Genel OCR Teorisi) adı verilen yeni bir evrensel optik karakter tanıma (OCR) modeli oluşturdular. Araştırmacılar yayınladıkları makalede, geleneksel OCR sistemlerinin ve büyük dil modellerinin güçlü yönlerini birleştirmeyi amaçlayan OCR 2.0 konseptini tanıttı.
Araştırmacılara göre OCR 2.0 modeli, birleşik uçtan uca mimari kullanıyor ve büyük dil modellerine kıyasla daha az kaynak gerektiriyor. Ayrıca, düz metinden daha fazlasını tanıyabilecek kadar da çok yönlü.
GOT’un mimarisi yaklaşık 80 milyon parametreye sahip bir görüntü kodlayıcı ve 500 milyon parametreye sahip bir konuşma kod çözücüden oluşuyor. Kodlayıcı 1.024 x 1.024 piksel görüntüleri belirteçlere sıkıştırır ve kod çözücü daha sonra bunları 8.000 karaktere kadar metne dönüştürüyor.
‘OCR 2.0’ bilim, müzik ve analitikte karmaşık görsel verilerin otomatik işlenmesinin kilidini açıyor
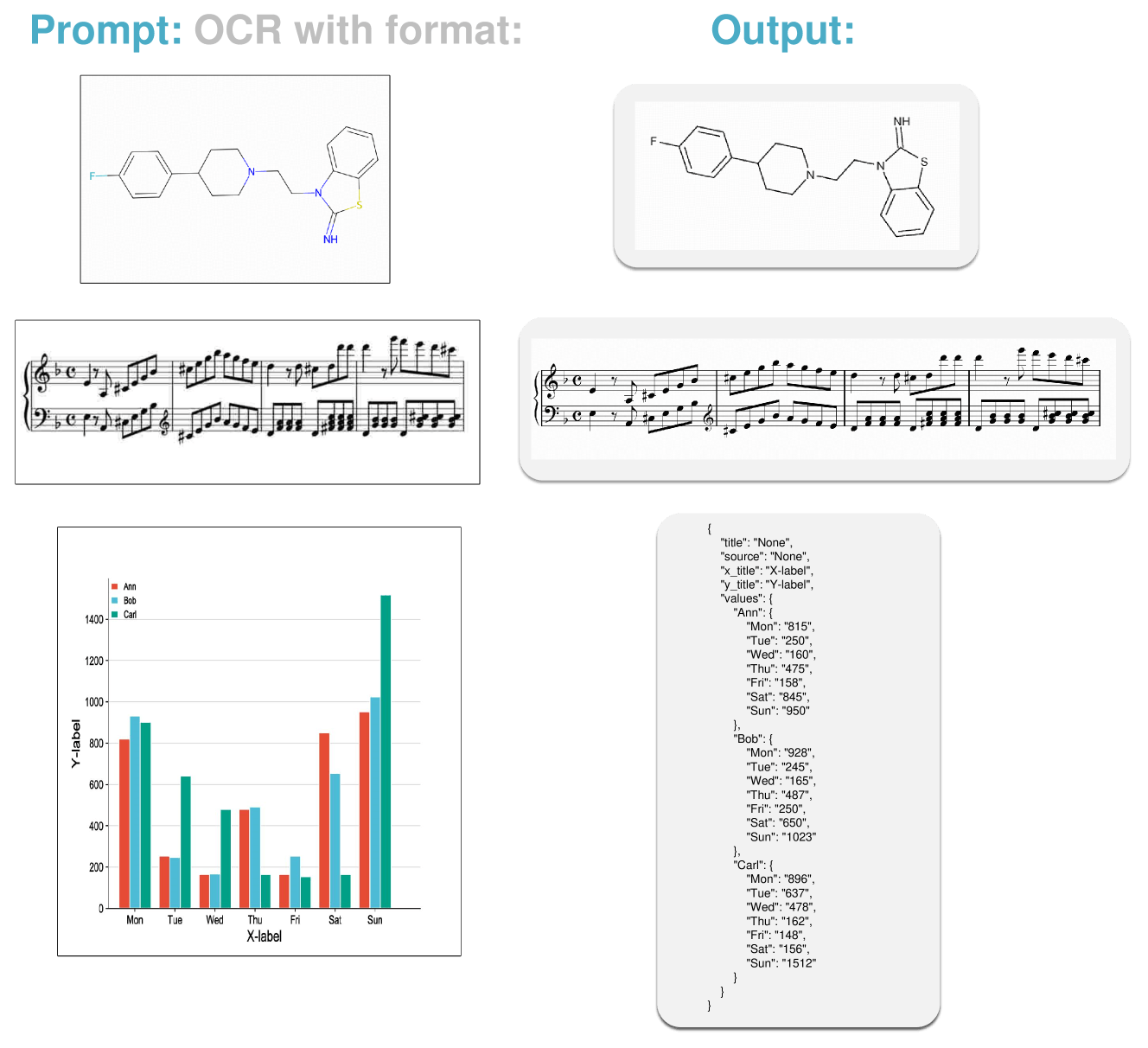
Yeni model çeşitli görsel bilgi türlerini tanıyabilir ve düzenlenebilir metne dönüştürebilir. Bunlara İngilizce ve Çince sahne metinleri ve belge metinleri, matematiksel ve kimyasal formüller, müzik notaları, basit geometrik şekiller ve bileşenleriyle diyagramlar dahil.
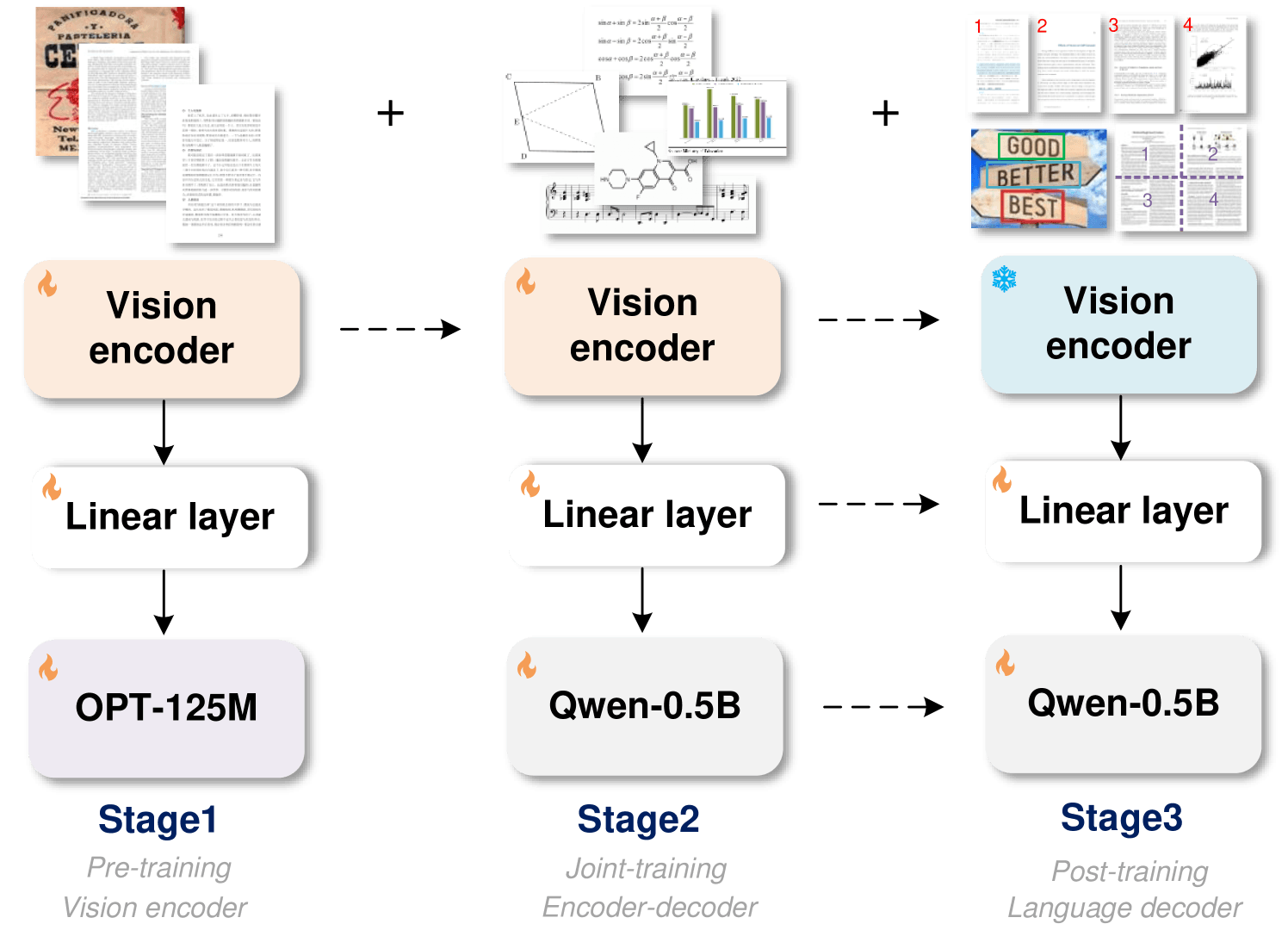
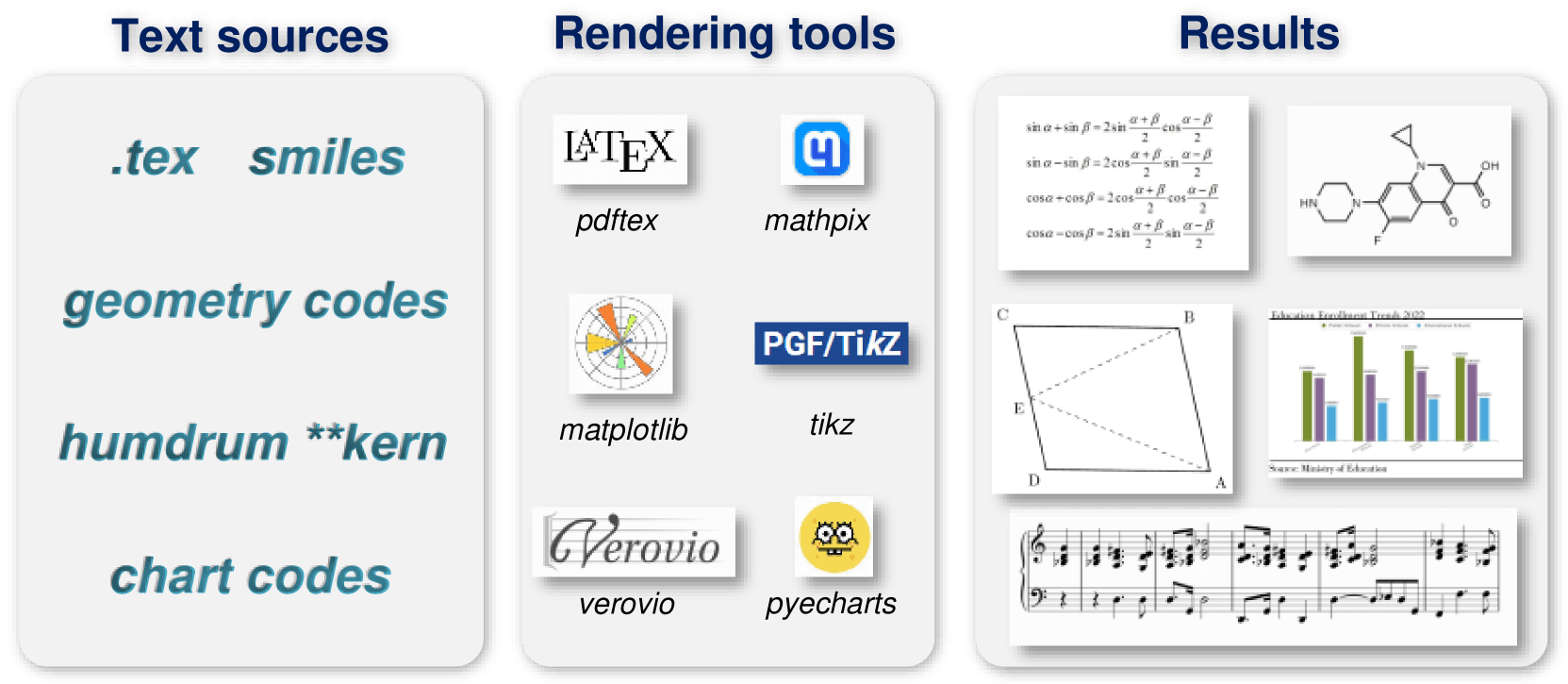
Eğitimi optimize etmek için araştırmacılar önce yalnızca kodlayıcıyı metin tanıma görevlerinde eğittiler. Daha sonra Alibaba’nın Qwen-0.5B’sini bir kod çözücü olarak eklediler ve tüm modeli çeşitli, sentetik verilerle ince ayarladılar. Ekip, eğitim için milyonlarca resim-metin çifti oluşturmak üzere LaTeX, Mathpix-markdown-it, TikZ, Verovio, Matplotlib ve Pyecharts gibi işleme araçlarını kullandı.

Araştırmacılar, GOT’un modüler tasarımının ve sentetik veri eğitiminin esnek genişlemeye izin verdiğini bildiriyor. Tüm modeli yeniden eğitmeden yeni yetenekler eklenebilir. Bu yaklaşımın, zaman içinde sistemde verimli güncellemeler ve iyileştirmeler sağladığını söylüyorlar.
Deneylerde, GOT çeşitli OCR görevlerinde iyi performans gösterdi. Belge ve sahne metin tanımada en yüksek puanları aldı, hatta diyagram tanımada uzmanlaşmış modelleri ve büyük dil modellerini geride bıraktı.
Araştırmacılar, başkalarının da kullanıp geliştirebilmesi için Hugging Face’te ücretsiz bir demo ve kod yayınladılar.
Kaynak: The Decoder
Yapayzeka.news’in hiçbir güncellemesini kaçırmamak için bizi Facebook, X (Twitter), Bluesky, LinkedIn, Instagram ve Whatsapp Kanalımız‘dan takip edin.


 adı verilen yeni bir evrensel optik karakter tanıma (OCR) modeli oluşturdular.){kind=link}