
NVIDIA, Mistral AI ile iş birliği yaparak, son derece gelişmiş bir açık erişimli büyük dil modeli (LLM) olan Mistral-NeMo-Minitron 8B modelinin piyasaya sürüldüğünü duyurdu. NVIDIA Teknik Blog’una göre, bu model dokuz popüler kıyaslamada doğruluk açısından benzer boyuttaki diğer modelleri geride bırakıyor.
Gelişmiş Model Budama ve Damıtma
Mistral-NeMo-Minitron 8B modeli, daha büyük Mistral NeMo 12B modelinin genişlik budamasıyla ve ardından bilgi damıtımı kullanılarak hafif bir yeniden eğitim süreciyle geliştirildi. Başlangıçta NVIDIA’nın Budama ve Bilgi Damıtması ile Kompakt Dil Modelleri makalesinde önerilen bu metodoloji, NVIDIA Minitron 8B ve 4B modelleri ile Llama-3.1-Minitron 4B modeli de dahil olmak üzere birden fazla başarılı uygulama ile doğrulandı.
Model budaması, katmanları (derinlik budaması) veya nöronları ve dikkat başlıklarını (genişlik budaması) düşürerek bir modelin boyutunu ve karmaşıklığını azaltmayı içeriyor. Bu süreç genellikle kaybedilen doğruluğu geri kazanmak için yeniden eğitimle eşleştiriliyor. Öte yandan model damıtması, bilgiyi büyük, karmaşık bir modelden (öğretmen modeli) daha küçük, daha basit bir modele (öğrenci modeli) aktarır ve daha verimli olurken orijinal modelin tahmin gücünün çoğunu korumayı amaçlıyor.
Budama ve damıtmanın birleşimi, büyük bir önceden eğitilmiş modelden giderek daha küçük modeller oluşturulmasına olanak tanıyor. Bu yaklaşım, sıfırdan eğitim için gereken çok daha büyük veri kümelerine kıyasla, yeniden eğitim için yalnızca 100-400 milyar token’a ihtiyaç duyulduğundan hesaplama maliyetini önemli ölçüde azaltıyor.
Mistral-NeMo-Minitron 8B Performansı
Mistral-NeMo-Minitron 8B modeli, Llama 3.1 8B ve Gemma 7B modelleri de dahil olmak üzere sınıfındaki diğer modellerden daha iyi performans göstererek birçok kıyaslamada lider doğruluk sergiliyor. Aşağıdaki tablo performans ölçümlerini vurguluyor:
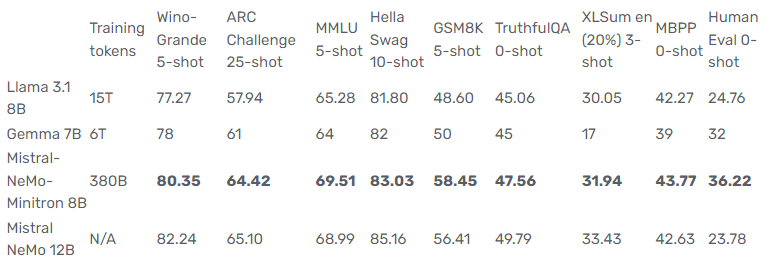
Tablo 1. Mistral-NeMo-Minitron 8B temel modelinin Mistral-NeMo-Minitron 8B temel modelinin öğretmen Mistral-NeMo 12B, Gemma 7B ve Llama-3.1 8B temel modellerine kıyasla doğruluğu. Kalın sayılar 8B model sınıfı arasında en iyisini temsil etmektedir.
Uygulama ve Gelecekteki Çalışmalar
Yapılandırılmış ağırlık budaması ve bilgi damıtmasının en iyi uygulamalarını takiben, Mistral-NeMo 12B modeli 8B hedef modelini üretmek için genişlik budandı. Süreç, dağıtım kaymalarını düzeltmek için 127 milyar token kullanarak budanmamış Mistral NeMo 12B modelinin ince ayarını yapmayı, ardından 380 milyar token kullanarak yalnızca genişlik budaması ve damıtmayı içeriyordu.
Mistral-NeMo-Minitron 8B modeli üstün performans ve verimlilik sergiliyor ve bu da onu yapay zeka alanında önemli bir ilerleme haline getiriyor. NVIDIA, daha küçük ve daha doğru modeller üretmek için damıtma sürecini iyileştirmeye devam etmeyi planlıyor. Bu tekniğin uygulanması, üretken yapay zeka için NVIDIA NeMo çerçevesine kademeli olarak entegre edilecek.
Yapayzeka.news’in hiçbir güncellemesini kaçırmamak için bizi Facebook, X (Twitter), Bluesky, LinkedIn, Instagram ve Whatsapp Kanalımız‘dan takip edin.


{kind=link}