
Yeni bir hakemli çalışma, OpenAI’nin GPT-4 dil modelinin herhangi bir ek eğitime ihtiyaç duymadan Japonya Ulusal Fizik Tedavi Sınavı’nı geçebileceğini gösterdi.
Cureus dergisinde yayınlanan araştırmada, GPT-4 hem metin hem de görsel sorularda test edildi. Japonya’nın fizyoterapist sınavı, hafıza, kavrama, uygulama, analiz ve değerlendirmeyi test eden 160 genel ve 40 pratik sorudan oluşuyor.
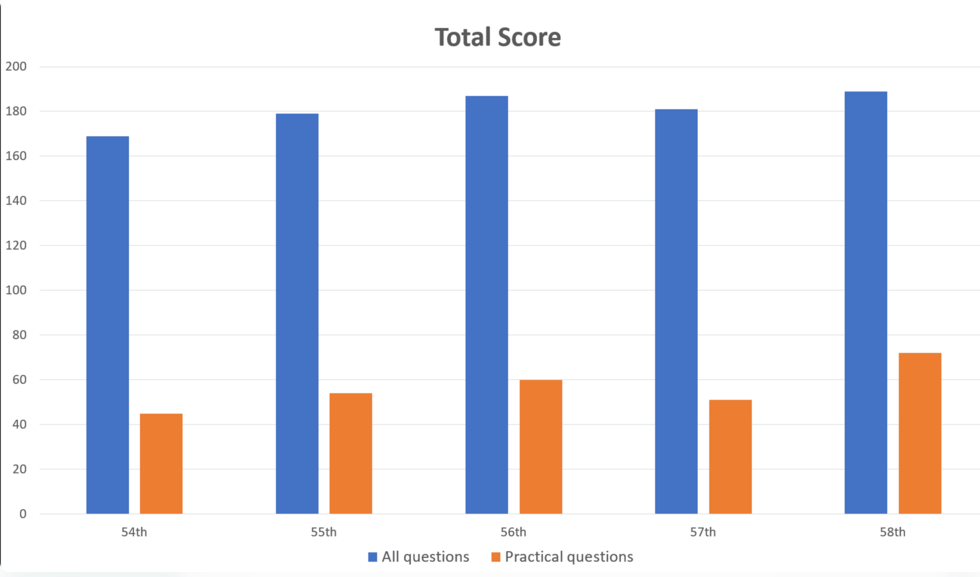
Araştırmacılar GPT-4’e 1.000 soru girdiler ve cevapları resmi çözümlerle karşılaştırdılar. GPT-4 beş test bölümünün hepsini geçti ve soruların genel olarak %73,4’ünü doğru cevapladı. Ancak, YZ teknik sorularda ve resim veya tablo içeren sorularda zorlandı.

Model genel sorularda (doğru %80,1) pratik sorulardan (doğru %46,6) çok daha iyi performans gösterdi. Benzer şekilde, GPT-4 yalnızca metin içeren soruları (doğru %80,5) resim ve tablo içeren sorulardan (doğru %35,4) çok daha iyi ele aldı. Bu bulgular GPT-4’ün görsel kavrama sınırlamaları üzerine yapılan önceki araştırmalarla örtüşüyor.
İlginçtir ki, soru zorluğu ve metin uzunluğu GPT-4’ün performansını önemli ölçüde etkilemedi. Model, öncelikli olarak İngilizce verilerle eğitilmiş olmasına rağmen Japonca girdiyle de iyi performans gösterdi.
Çok modlu modeller daha fazla iyileştirme sağlayabilir
Çalışma GPT-4’ün klinik rehabilitasyon ve tıp eğitimindeki potansiyelini gösterirken, araştırmacılar tüm soruları doğru şekilde yanıtlamadığı konusunda uyarıyor. Daha yeni sürümlerin ve modelin yazılı ve muhakeme testlerindeki yeteneklerinin değerlendirilmesi gerektiğini vurguluyorlar. GPT-4o gibi çok modlu modeller görsel kavramada potansiyel olarak daha iyi sonuçlar verebilir.
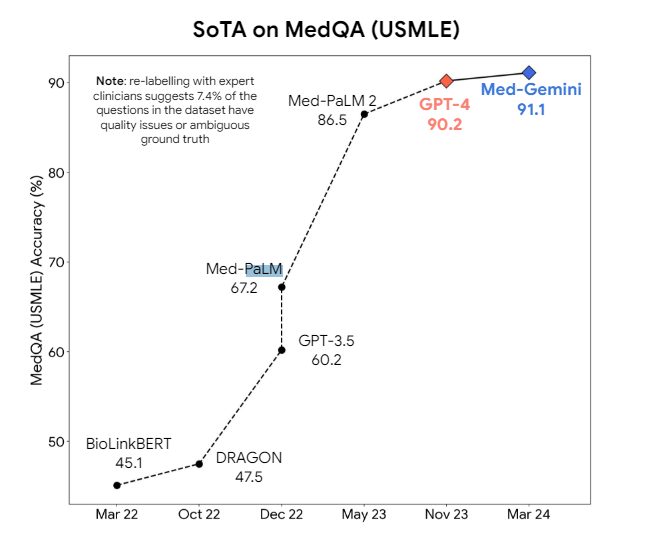
Büyük dil modelleri bir süredir tıpta umut vadediyor. Google’ın Med-PaLM 2 ve Med-Gemini gibi özel versiyonlar, tıbbi görevlerde GPT-4 gibi genel modellerden daha iyi performans göstermeyi hedefliyor. Meta’da ayrıca tıbbi sektör için tasarlanmış Llama 3 tabanlı modeller de var.
Ancak, tıbbi AI modellerinin pratikte yaygın olarak kullanılmasının uzun zaman alması muhtemel. Mevcut ölçütler bile, özellikle tıbbi bağlamlarda kritik olan çok fazla hata payı bırakıyor. Kesinlik ve doğruluğun önemli olduğu diğer birçok uygulamada olduğu gibi, bu modelleri günlük pratiğe güvenli bir şekilde entegre etmek için akıl yürütme becerilerinde önemli iyileştirmeler gerekli görünüyor.
Yapayzeka.news’in hiçbir güncellemesini kaçırmamak için bizi Facebook, X (Twitter), Bluesky, LinkedIn, Instagram ve Whatsapp Kanalımız‘dan takip edin.


{kind=link}