
Google DeepMind, Gemini 1.5 Pro’nun geniş bağlam penceresi ve çok modlu giriş yeteneklerini kullanarak robotların karmaşık ortamlarda nasıl gezinebileceğini gösterdi.
Araştırmacılar, robotların yalnızca insan talimatları, video rehberliği ve model muhakemesi kullanarak bilinmeyen alanlarda gezinmesini sağlamak için Gemini 1.5 Pro’nun bir milyona kadar çok modlu token işleme yeteneğini kullandılar.
Bir deneyde, bilim insanları robotları gerçek dünya ortamının belirli bölgelerinde yönlendirerek onlara “Lewi’nin masası” veya “geçici masa alanı” gibi önemli yerleri gösterdiler. Robotlar daha sonra kendi başlarına bu yerlere geri dönmeyi başardılar.
Robotun çevreyi genel hatlarıyla görmesini sağlayan “tanıtım videosu” akıllı telefonla kolayca kaydedilebiliyor.
Bu yaklaşım küçük nesneler için bile işe yarar. Bir kullanıcı robota evinin video turunu gösterebilir ve daha sonra akıllı telefonuyla “Rock’ımı nerede bıraktım?” diye sorabilir. Robot daha sonra kendi kendine konuma gider.
Dahili dil modeli sayesinde robot soyutlamalar da yapabilir. Bir kullanıcı çizim yapmak için bir yer isterse, robot bunu bir beyaz tahtayla ilişkilendirebilir ve kullanıcıyı oraya götürebilir.
Google DeepMind, gelecekte bir robotun bir kullanıcının tercihlerini görsel-işitsel bilgilerden çıkarabileceğini ve buna göre hareket edebileceğini öne sürüyor. Örneğin, bir kullanıcının masasında belirli bir markanın birçok kutusu varsa, robot o içeceği tercihen buzdolabından alabilir. Bu tür yetenekler insan-robot etkileşimini büyük ölçüde artırabilir.
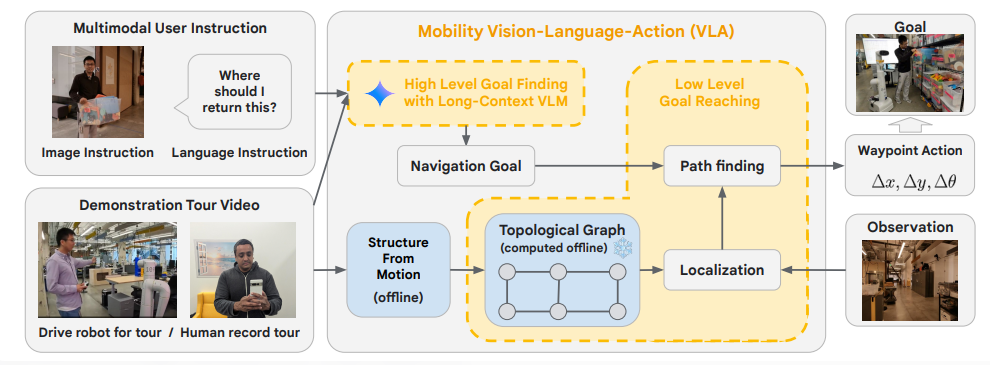
Sistem mimarisi, odanın basitleştirilmiş bir temsili olan topolojik bir grafik oluşturmak için çok modlu girdiyi işler. Bu grafik, video turlarının bireysel görüntülerinden oluşturulur ve ortamın genel bağlantısını yakalayarak robotun ayrıntılı bir harita olmadan gezinmesine olanak tanır.
Daha ileri testlerde robotlar, beyaz tahtada harita çizimleri, turdaki konumlarla ilgili sesli uyarılar ve oyuncak kutusu gibi görsel ipuçları gibi ek çok modlu talimatlar aldı. Bu girdilerle robotlar farklı kişiler için farklı görevler gerçekleştirebildi.
Mobility VLA, 836 metrekarelik gerçek bir ofis ortamında yapılan 57 testte çeşitli çok modlu navigasyon görevlerini gerçekleştirmede %90’a varan başarı oranlarına ulaştı. Mantık gerektiren karmaşık talimatlar için, metin tabanlı bir sistem için %60 ve CLIP tabanlı bir yaklaşım için %33’e kıyasla %86’lık bir başarı oranına ulaştı.

Umut verici sonuçlara rağmen araştırmacılar bazı sınırlamalara işaret ediyor. Örneğin, sistem şu anda bir komutu işlemek için 10 ila 30 saniye harcıyor ve bu da etkileşimde gecikmelere neden oluyor. Ayrıca ortamı kendi başına keşfedemiyor, bunun yerine sağlanan gösteri videosuna güveniyor.
Google Deepmind, Mobility VLA’yı diğer robot platformlarına genişletmeyi ve sistemin yeteneklerini navigasyonun ötesine taşımayı planlıyor. Ön testler, sistemin nesneleri incelemek ve sonuçları raporlamak gibi daha karmaşık görevleri de gerçekleştirebileceğini gösteriyor.
Yapayzeka.news’in hiçbir güncellemesini kaçırmamak için bizi Facebook, X (Twitter), Bluesky, LinkedIn, Instagram ve Whatsapp Kanalımız‘dan takip edin.


{kind=link}