
Alibaba’nın AI laboratuvarı, yaklaşık on romana eşdeğer bir milyona kadar metin tokenini işleyebilen Qwen dil modelinin yeni bir versiyonunu tanıttı. Ekip ayrıca işleme hızını dört katına çıkarmayı başardı.
Qwen, Eylül ayında tanıtılan Qwen2.5 dil modelini 128.000’den 1 milyon jetonluk bir bağlam uzunluğuna genişletti. Bu, Qwen2.5-Turbo’nun on tamamlanmış romanı, 150 saatlik transkripti veya 30.000 satır kodu işlemesine olanak tanıyor.
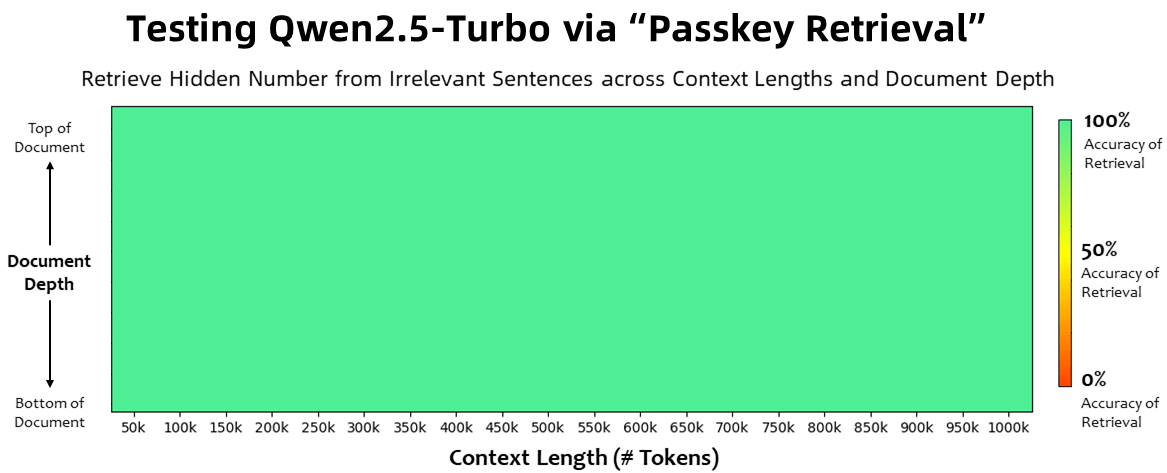
Sayı almada %100 doğruluk
1 milyon alakasız metin belirteci içindeki gizli sayıları bulmayı gerektiren geçiş anahtarı alma görevinde, model bilginin belgedeki konumundan bağımsız olarak %100 doğruluk elde eder. Bu, dil modellerinin öncelikle bir istemin başlangıcını ve sonunu dikkate aldığı “ortada kaybolma” olgusunu kısmen aşmış gibi görünüyor.
Uzun metin anlayışı için çeşitli ölçütlerde Qwen2.5-Turbo, GPT-4 ve GLM4-9B-1M gibi rakip modellerden daha iyi performans gösterir. Aynı zamanda, kısa dizilerdeki performansı GPT-4o-mini ile kıyaslanabilir kalıyor.
Qwen, bir ekran kaydında yeni dil modelinin Cixin Liu’nun toplam uzunluğu 690.000 jeton olan “Trisolaris” üçlemesinin tamamını hızlı bir şekilde özetleme yeteneğini gösteriyor. | Video: Qwen
Seyrek dikkat, çıkarımı 4,3 kat hızlandırıyor
Qwen, seyrek dikkat mekanizmaları kullanarak 1 milyon tokeni işlerken ilk tokene ulaşma süresini 4,9 dakikadan 68 saniyeye düşürdü. Bu, 4,3 kat hız artışı anlamına geliyor.

Fiyat 1 milyon token başına 0,3 yuan (4 sent) olarak kalıyor. Aynı maliyetle, Qwen2.5-Turbo, GPT-4o-mini’den 3,6 kat daha fazla token işleyebilir.
Qwen2.5-Turbo artık Alibaba Cloud Model Studio’nun API’si ve HuggingFace ve ModelScope’taki demolar aracılığıyla kullanılabilir.
Qwen uzun dizilerde iyileştirmeye açık alan olduğunu kabul ediyor
Şirket, mevcut modelin gerçek uygulamalarda uzun dizilere sahip görevleri çözerken her zaman tatmin edici bir performans göstermediğini kabul ediyor.
Modelin uzun dizilerde daha az kararlı performans göstermesi ve daha büyük modellerin kullanılmasını zorlaştıran yüksek çıkarım maliyetleri gibi çözülmemiş birçok zorluk bulunuyor.
Qwen, uzun diziler için insan tercihi uyumunu daha fazla araştırmayı, hesaplama süresini azaltmak için çıkarım verimliliğini optimize etmeyi ve uzun bağlamlı daha büyük ve daha yetenekli modelleri pazara sunmak için çalışmayı planlıyor.
Büyük bağlam pencerelerinin faydası nedir?
Büyük dil modellerinin bağlam pencereleri son aylarda istikrarlı bir şekilde büyüdü. Pratik bir standart şu anda 128.000 (GPT-4o) ile 200.000 (Claude 3.5 Sonnet) jeton arasında yerleşmiş durumda, ancak 10 milyona kadar jetonlu Gemini 1.5 Pro veya 100 milyon jetonlu Magic AI’nin LTM-2-mini gibi uç değerler de var.
Bu gelişmeler genel olarak büyük dil modellerinin kullanışlılığına katkıda bulunsa da, yapılan çalışmalar, ek bilgilerin vektör veritabanlarından dinamik olarak alındığı RAG sistemleriyle karşılaştırıldığında büyük bağlam pencerelerinin avantajına tekrar tekrar şüpheyle yaklaşıyor.
Yapayzeka.news’in hiçbir güncellemesini kaçırmamak için bizi Facebook, X (Twitter), Bluesky, LinkedIn, Instagram ve Whatsapp Kanalımız‘dan takip edin.


{kind=link}