
Tsinghua Üniversitesi, Şangay Yapay Zeka Laboratuvarı ve 01.AI’dan araştırmacılar, karışık veri kalitesine sahip açık kaynaklı dil modellerini iyileştirmek için OpenChat adlı yeni bir çerçeve geliştirdi.
Herkesin program kodunu incelemesine ve anlamasına olanak tanıyan LLaMA ve LLaMA2 gibi açık kaynaklı dil modelleri, genellikle denetimli ince ayar (SFT) ve takviyeli öğrenme ince ayarı (RLFT) gibi özel teknikler kullanılarak rafine edilir ve optimize edilir.
Ancak bu teknikler, kullanılan tüm verilerin aynı kalitede olduğunu varsayar. Ancak pratikte, bir veri seti tipik olarak en iyi ve nispeten kötü verilerin bir karışımından oluşur. Bu durum dil modellerinin performansına zarar verebilir.
OpenChat bu sorunu çözmek için Koşullu RLFT (C-RLFT) adı verilen yeni bir yöntem kullanıyor. Bu yöntem, farklı veri kaynaklarını, özellikle tercih edilen verileri etiketlemeye gerek kalmadan, kaba ödül etiketleri olarak hizmet eden farklı sınıflar olarak ele alıyor. Basitçe söylemek gerekirse, sistem bazı verilerin mükemmel olduğunu, diğer verilerin ise nispeten zayıf olduğunu öğrenir ve verileri açıkça etiketlemek zorunda kalmadan buna göre ağırlıklandırır.
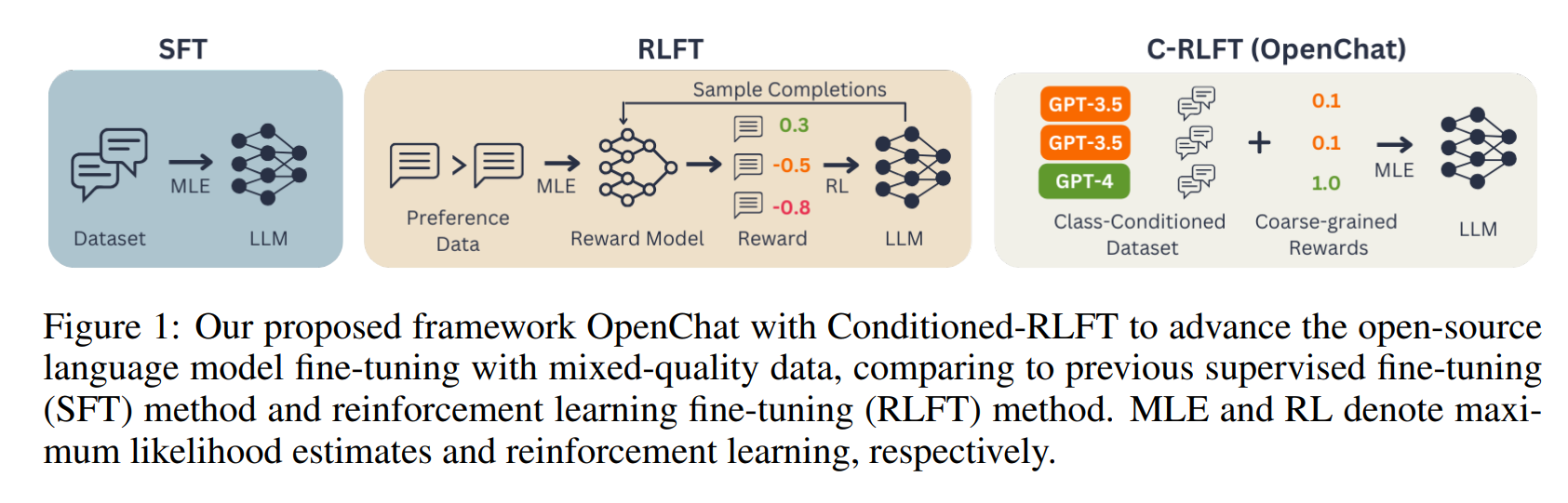
C-RLFT karmaşık takviyeli öğrenme veya pahalı insan geri bildirimi gerektirmediğinden uygulaması nispeten kolay. Araştırmacılara göre, yapay zekanın takviyeli öğrenme gibi deneme-yanılma yöntemlerine başvurmak zorunda kalmadan doğru cevaplara sahip birkaç örnekten öğrendiği tek adımlı RL’siz denetimli öğrenme yeterlidir. Bu da zaman ve hesaplama tasarrufu sağlıyor.
C-RLFT kıyaslamalarda potansiyel gösteriyor
C-RLFT’nin diğer yöntemlere göre çeşitli avantajları vardır. İyi ve kötü verilerin bir karışımıyla çalışabildiği için veri kalitesine daha az bağımlı. Karmaşık öğrenme ve değerlendirme süreçleri gerektirmediği için yöntemin uygulanması diğerlerine göre daha kolay ve özellikle farklı veri niteliklerini kullandığı için sağlamdır. Pahalı insan geri bildirimine dayanmadığı için C-RLFT aynı zamanda uygun maliyetli.
İlk testlerde, C-RLFT ile rafine edilen OpenChat 13b modeli, test edilen diğer tüm dil modellerinden daha iyi performans göstermiş ve hatta MT tezgahında Llama 2 70B gibi çok daha büyük modellerden daha iyi performans gösterebilmiştir.
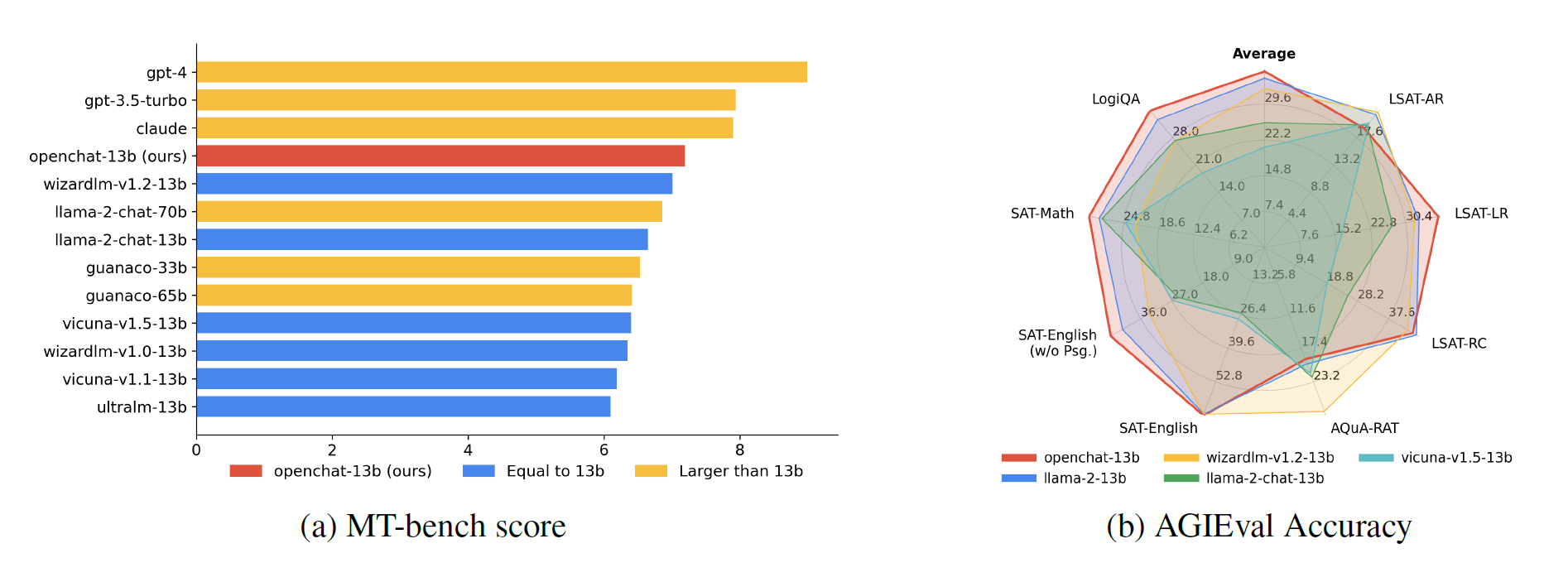
Yukarıdaki kıyaslamalar Eylül sonundaki C-RLFT makalesinden alındı. Araştırma ekibine göre, Kasım ayı başında yayınlanan 8K bağlam pencereli OpenChat 3.5-7B modeli bazı kıyaslamalarda ChatGPT’den bile daha iyi performans gösterdi.
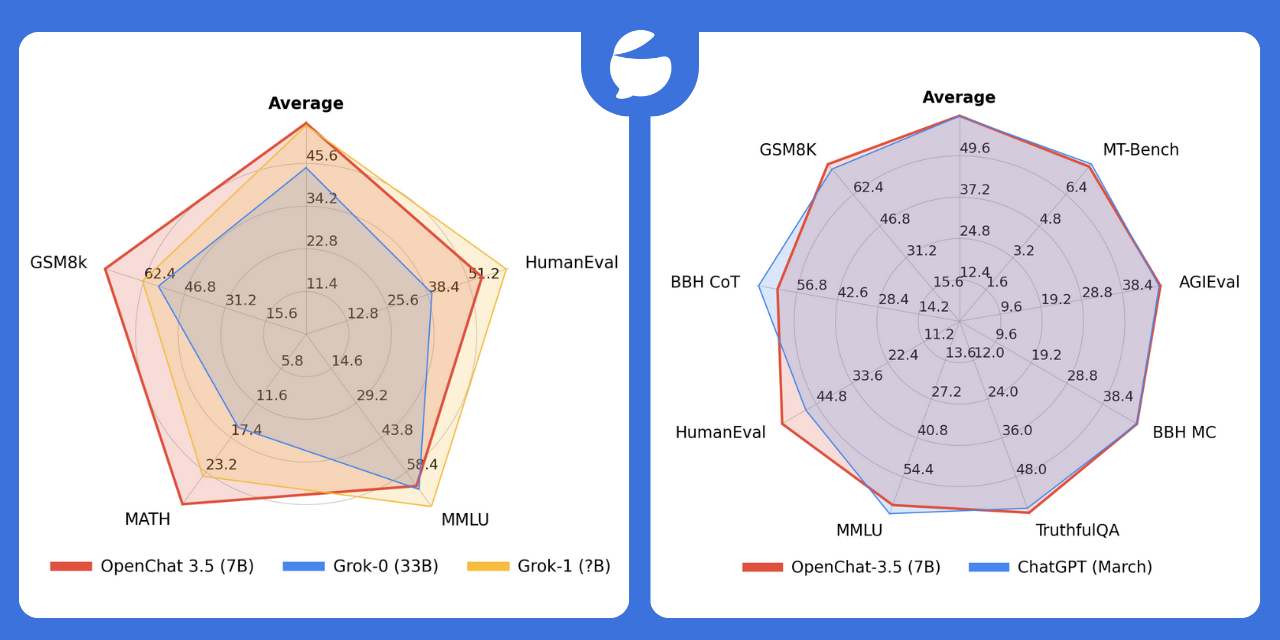
Araştırmacılar iyileştirme için alan görüyor. Örneğin, ödüllerin farklı veri kaynakları arasındaki dağılımı daha da iyileştirilebilir. Bu yöntem gelecekte dil modellerinin mantıksal akıl yürütme gibi diğer alanlardaki yeteneklerini geliştirmek için de kullanılabilir.
OpenChat çerçevesi ve ilgili tüm veriler ve modeller Github’da herkese açıktır. Çevrimiçi bir demo burada mevcuttur. OpenChat v3 modelleri Llama’ya dayanmaktadır ve Llama lisansı altında ticari olarak kullanılabilir.
Kaynak: The-Decoder
Yapayzeka.news’in hiçbir güncellemesini kaçırmamak için bizi Facebook, Twitter, LinkedIn, Instagram‘ ve Whatsapp Kanalımız‘dan takip edin.


{kind=link}